How AI is helping us solve a challenge that has limited research information management for more than two decades
The Problem We Set Out to Solve
When a few of us started Symplectic in 2002, friends first, a company somewhat later, the idea was simple: Academics were spending time they didn’t have on administration they didn’t want to do, and a surprising amount of that time went on the single, repetitive task of telling one system or another what they had published.
The annual review wanted it. The grant application wanted it. The departmental return wanted it. The web profile wanted it. Each asked the same question, and each expected the answer freshly typed.
So, more than 20 years ago, we built a place to hold the answer once. Keep a clean, central record of a person’s outputs, and let every downstream process draw on it rather than demand it again. Put like that, it sounds like plumbing, and it largely was. But the value of plumbing is that you stop thinking about it, and that was rather the point: to give people back the one thing none of us has enough of.
Before AI, We Started with What Universities Already Knew
The real “genius”, such as it was, lay not in the database but in doing crowd sourcing before crowd sourcing was a thing. Universities already had access to PubMed, Web of Science and Scopus. For many academics, the data were sitting there in systems that universities either had access to or to which they were already subscribing.
Symplectic Elements simply went and fetched publications and asked them to confirm that the publications were theirs – and saved them the typing. We weren’t asking academics to do more work; we were asking them to do less, using assets their library already had access to.
That framing augment: “Don’t add burden” – has been the golden thread of everything we’ve built since.
Over the years there was a great deal to build. The two or three sources that we had covered medicine, science and most of engineering. But that was never going to do a good job for colleagues in the SHAPE (Social Sciences, Humanities, and the Arts for People and the Economy) disciplines – or those that were heavily conference based, book-based or where publications appeared in non-English-speaking venues.
We added RePEc for the economists, DBLP for the computer scientists, Google Books for book-centric disciplines, Crossref for anyone moving to the DOI system, and a long tail of others besides. Each new connector pulled another slice of the scholarly record into view.
Over time, advances in technology, we’ve tried to get this closer to a “magic” experience: log in, and your work is simply *there*, already confirmed, open access full text identified and made available to your local institutional repository.
The Limits of the Scholarly Record
But there was a stubborn limit to the magic, and we knew exactly where it lived.
For all the databases Symplectic Elements could reach, we could never find everything. Beneath the surface was an uncomfortable inequity between disciplines. The harvesting model that worked so beautifully for a geneticist quietly failed the people in law, in linguistics, and across great swathes of the arts and humanities.
Their record existed. It simply didn’t live in any database we could connect to.
It lived, of course, in their CV.
The Holy Grail: Understanding the CV
Parsing the CV became something of a holy grail. We talked about it for years.
The problem was never one of ambition; it was that a CV is gloriously, defiantly unstructured. Every academic keeps theirs differently. The formatting is personal, the categories idiosyncratic, the conventions discipline-specific to the point of being a private language.
Conventional software hates exactly this kind of input, the human-readable document that resists being read by a machine. For a long time, the honest answer was that the technology simply wasn’t equal to the task.
What changed wasn’t the importance of the problem but the ability of machines to understand unstructured information at scale.
That answer has changed.
When the Technology Finally Caught Up
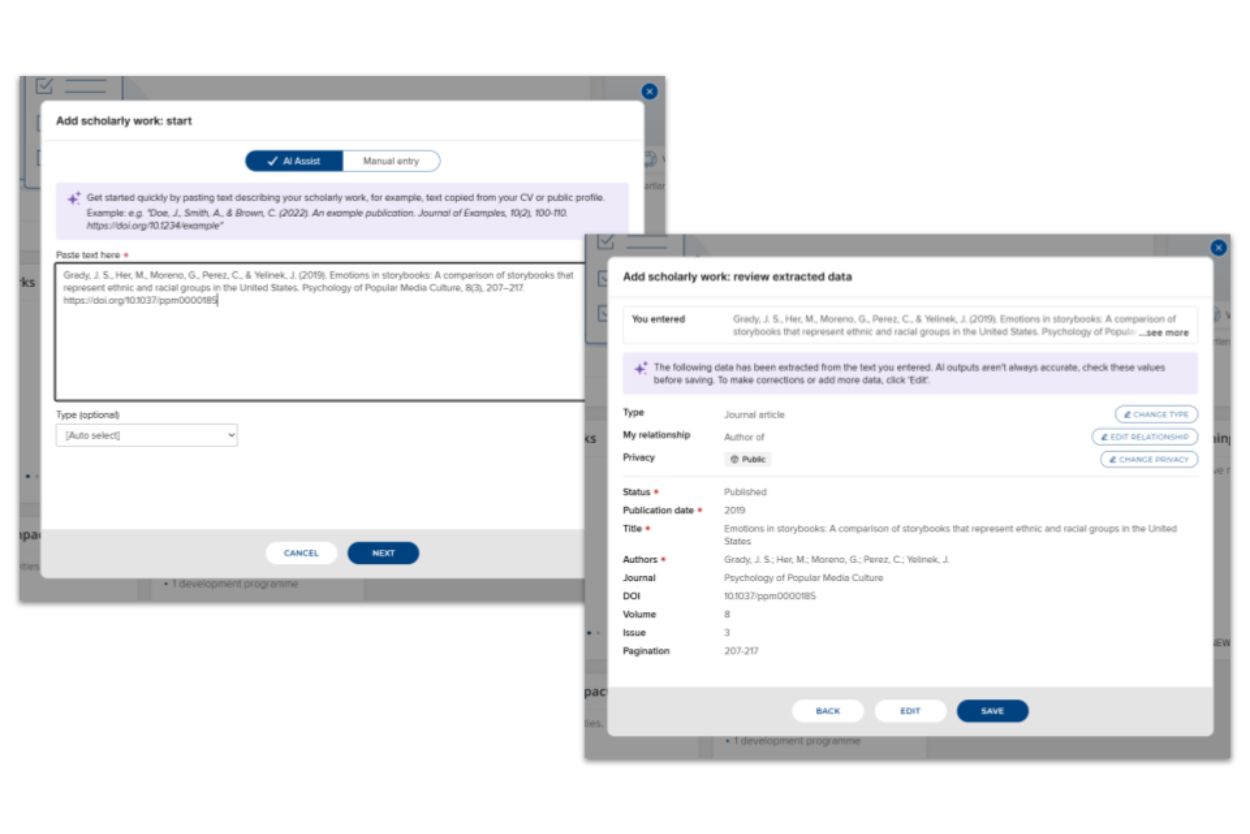
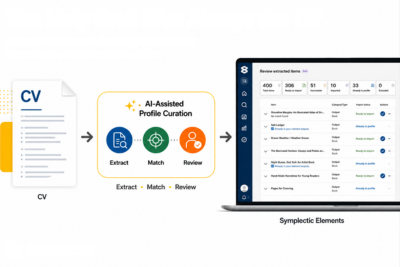
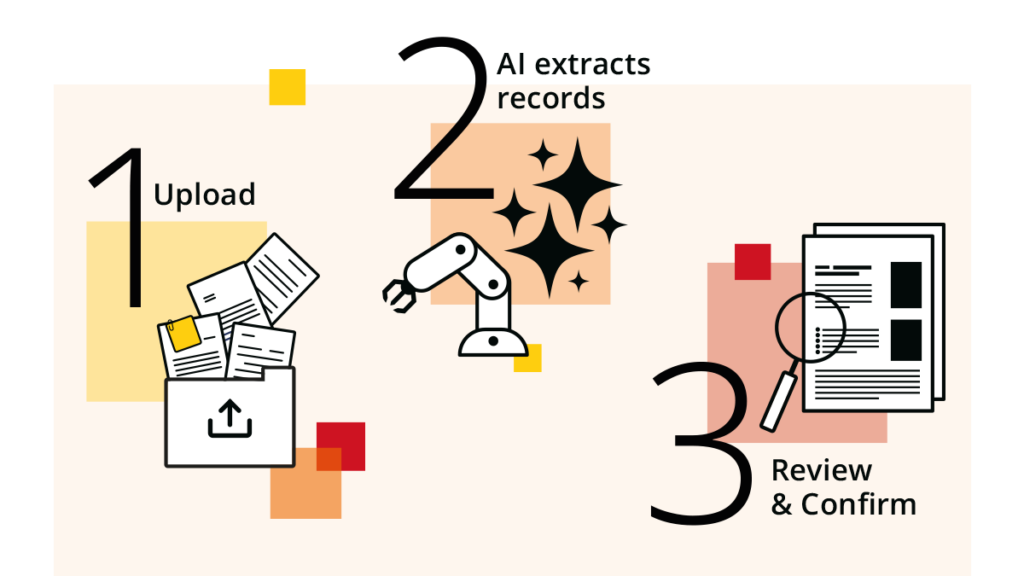
With the new AI-Assisted Profile Curation capabilities, and the CV import feature in particular, a researcher or an administrator can drop a document — a CV, or even plain text — into Symplectic Elements and have it read, understood, and turned into structured records.
The metadata is extracted and organised, mapped to the institution’s own schema, checked against what’s already there to avoid duplicates, and then – this part matters – handed back to a person to review and confirm before anything is saved.
Drop a document and go.
The Mission Hasn’t Changed
I find the numbers quietly remarkable. Some institutions report spending, on average, around twenty hours assembling a complete profile for a single new faculty member.
Twenty hours, for one person, once.
Multiply that across a hiring season and it is no longer an inconvenience; it is a structural drag on the very people whose time we ought to be protecting. To compress that work into a few reviewed minutes is exactly the sort of burden reduction we set out to chase more than twenty years ago.
What pleases me most, though, is not the cleverness of the underlying models. It is that the mission hasn’t moved. In 2002 we used the databases an institution had already paid for to save academics from re-typing what was already known. In 2026 we use AI to read the one document where the rest of it has always lived.
The tools have changed beyond recognition; the intent has not changed at all.
We are still trying to give scholars back their time, and still trying to do it in a way that is augmentative, transparent, and safe, with a human firmly in the loop at the point of decision.
The holy grail, it turns out, was always the CV. For more than twenty years it held the part of the scholarly record that systems couldn’t easily reach. Today, we finally can—not because the mission changed, but because the technology finally caught up with it.