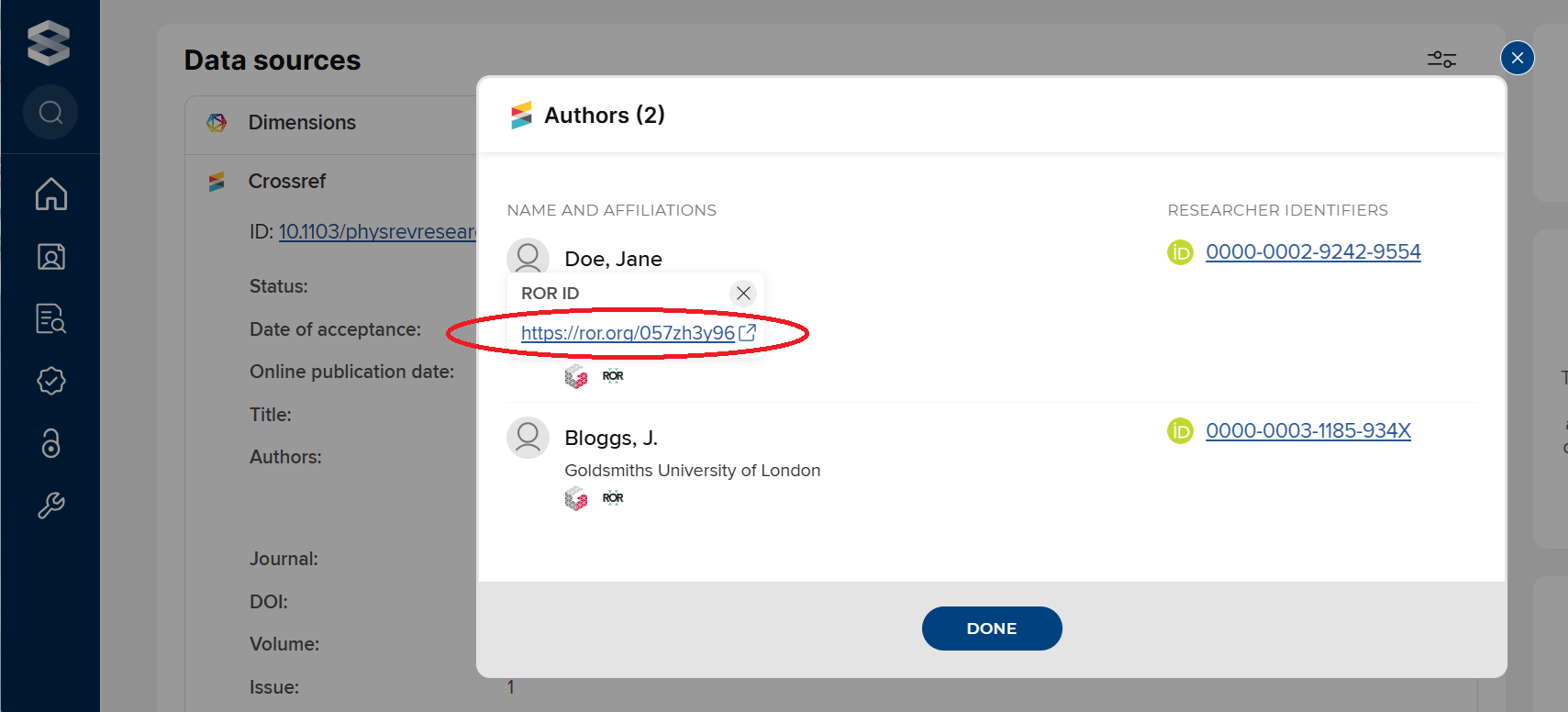
What’s the difference between The University of Oxford, and Oxford University?
Well, the first is the official name of the famed UK institution that’s over 900 years old. You’d expect to see this on a citation of a publication produced there.
The second clearly refers to the same place. It’s slightly faster to say, and uses fewer characters – which is why it appears on their Twitter account. You might see this appear in less formal communication about the University, and perhaps in casual conversation.
It’s not really a noticeable difference until it’s pointed out, but ambiguity between institution names is more of an issue than you might think.
There can be many names for a single institution, and many different ways of referring to them. In the above example, it’s easy to understand which institution we’re referring to, because it’s well-known. But what about those that aren’t so famous? A single city can have a ‘University Of, a ‘Metropolitan University’, an ‘Institute Of’, a ‘Royal College Of’, and so on. Each one of these can have a multitude of affiliated institutions. And then, we might have to think about affiliated institutions.
On top of that, a place name doesn’t always identify a location on its own. There are 32 Washingtons in the United States alone.
Washington University and the University of Washington are on opposite sides of the country.
How do we solve this problem when identifying researchers and their institutions?
The Global Research Identifier Database
In October, our partners at Digital Science celebrated the public launch of GRID, a “free, easy-to-use online database that opens up information about research organisations around the world to data scientists, developers and innovators within academic and commercial organisations.” It aims to solve the issues of ambiguity and messy data on research institutions (their name, location, organisation, website, etc), by curating clean, accurate information and making sure each institution is only listed once.
The GRID (Global Research Identifier Database) contains an individual, permanent ID for each institution. This is linked and browsable in the online database, and is free to download.
A great contribution to the open data landscape, the GRID team hope it will help open up data and information about research organisations across the world that has been previously hidden away.
It’s been utilised by some of the Digital Science portfolio companies already – Dimensions, figshare and Altmetric. But why is this relevant to us here at Symplectic?
In Elements, we routinely deal with disambiguation in terms of researcher names (for example, is J. Smith the same as John Smith? And if thousands share his name, how do we make sure his details are accurate?) Researchers are often linked to an institution where they conduct their research. So if an institution has 500 researchers, each producing 3 publications a year, with 5 co-authors at a time, with some cross-institutional collaboration, there’s going to be an awful lot of institutional identifiers in there. We’ve seen cases where a single large institution has over a million addresses linked to it.
When a record is being manually entered in Elements, an autocomplete prompt will show, suggesting the name of the institution as found in the GRID database.
This doesn’t just save the user time and effort (like the autocomplete on a Google search, for example), but critically, ensures they are selecting the correct institution without errors or variants. This ensures, as always, that the Elements system is populated with high-quality linked data.
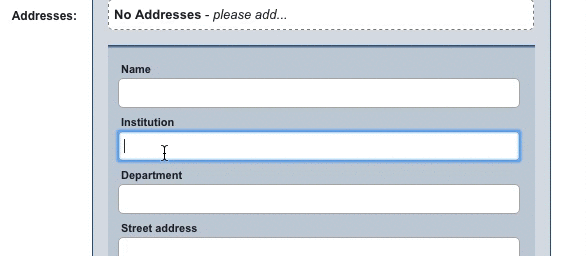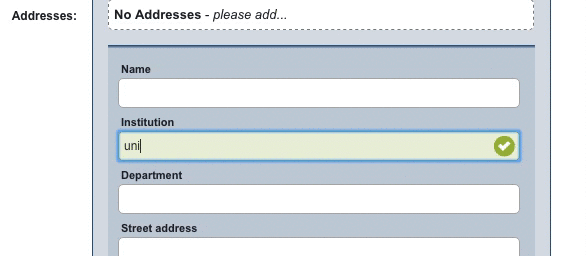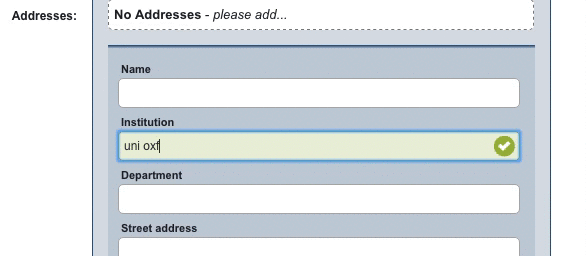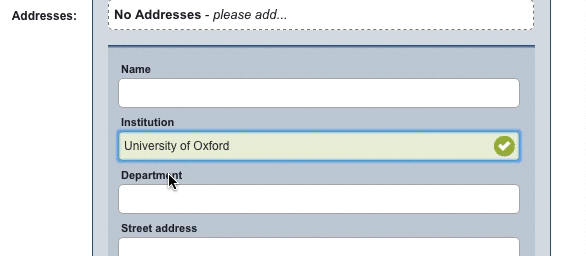
Currently, this integration ensures that manually-entered affiliation data matches institutional names in the GRID database. By automating this process, we cut out the need for manual disambiguation when using Elements data for reporting purposes. There are also possibilities for major enhancements to this in future – we’re looking at ways to potentially use the integration to disambiguate legacy affiliation data held in institutional systems.
And when used in conjunction with ORCID, this can provide yet another means for institutions to persistently link their researchers with scholarly works.
It’s been exciting to see the launch of GRID recently, and its positive reception throughout the research community. We look forward to seeing how it evolves and becomes ever more useful.
If you’d like to see GRID’s data for yourself right now, it’s available as a free download on the website, or you can browse through via their web interface.